Recently I read an interesting paper: A Contextual-Bandit Approach to Personalized News Article Recommendation. I noticed its dataset is available, so I thought to play with it. Here, I share a background theory and basic intermediate experimetnal results.
Suppose you are running a local news company that earns most of its advertisement impressions from your website. You want a system that makes a personalized recommendation for an article (item) to each site visitor (user). How do we design such a system? Well, Contextual Bandit (CB) algorithms could be a good option.
Exploration-Exploitation Dillemma
To motivate CB, let us add details to the story. Your workforce is quite big, so you have a constant influx of new items. Your site is also popular, so new users come and go often. Now, learning a recommender system in this setting is tricky. First, we would know very little about the new users and quite nothing about how they relate to existing users (similarity). The same for new items.
One way to resolve it is to passively wait and collect information about new users until we feel confident about their preferences. Then again, the call for a decision is upon us and we cannot serve them a blank page. Another way would be to make bold moves by carefully recommending articles to a new user such that each article effectively decreases the uncertainty about the user preference, all the while thinking about the best recommmendation for the user. Overall, this is called an exploration-exploitation dillemma. The user/item-changing nature makes it hard to apply popular recommendation algorithms like collaborative filtering or content-based filtering. Especially so, when there are not many data points (the cold-start problem). In contrast, Contextual Bandit by design balances between exploration and exploitation.
Multi-armed Bandit
 A multi-armed Bandit Problem. Credit: Microsoft Research.
A multi-armed Bandit Problem. Credit: Microsoft Research.
Suppose you are given $k$ actions . At each timestep , you take one action and receive a non-negative scalar reward $r_t \sim P_\theta(\cdot \vert a_t)$ where $\theta$ is the unknown parameters of a stationary distribution over rewards. Define the value of taking an action to be . Define the value of the optimal action . Define the regret of taking . From this, the expected regret after $T$ steps can be defined: where $n_j$ is the number of times $a_j$ was chosen over $T$ steps. Define the action value estimator . We hope to achieve $\mu_j \approx Q(a_j)$. In order to compute an optimal action, we would need to $\arg\max_j Q(a_j)$ (exploitation).
Then, again how do we explore? The general principle of CB for exploration is optimism under uncertainty. That is, if we are not sure about our $Q$ estimate for an action, we intentionally overestimate its action value such that we end up trying it out.
$\epsilon_n$-greedy
We just average all the rewards collected from taking $a_j$ over $T$ steps. . This is a sample mean estimator ($n_j$ estimates from one sample) and as such, it is unbiased. Since the main goal is to discover an optimal action (with the maximum expected reward), we need to try all actions at least once. To explore, we take an action chosen uniformly at random with a small probability $\epsilon$ and otherwise take a greedy decision . As we explore, we will have reduced enough uncertainty to conclude the optimal action. At that point, exploration would not be needed. Hence, we decay $\epsilon_1, \epsilon_2, \dots$ by a small factor (hyperparameter).
Upper Confidence Bound (UCB)
Suppose for each timestep $t$, we want to construct a confidence interval that keeps with a high probability that we can control. Suppose we decide how many steps we will play the game and let it be $n$. Furthermore, we assume in our formulation rewards are i.i.d. We assume the rewards are bounded. Then, using Hoeffding’s inequality, we can upper-bound the probability that our estimate deviates from the estimand by more than any constant $a > 0$ and show the bound can be made arbitrarily small with a large $n$. This leads to $c_j(t) = \sqrt{\frac{\log n}{ n_j(t) }}$ and we solve: . Of course, it is awkward to assume we know $n$ a priori. Auer et al1 proved a more natural bound $c_j(t) = \sqrt{\frac{2 \log t}{n_j(t)}}$.
Thompson Sampling
Thompson Sampling is a Bayesian kid for Multi-Armed Bandit. It follows the typical routine of posterior inference: a) set up a hypothesis (likelihood model) that is assumed to generate observations, b) define a prior over the model parameters, c) using Bayes rule, compute the posterior or the posterior predictive. In our case, we would model $P_\theta (r_t \vert a_t) \approx P_w(r_t \vert a_t)$ and define a prior over $\theta$. For certain combinations of likelihood model and prior that we can write the posterior down in a closed form (conjugate models), the exact inference is tractable. That said, in general, we know an exact Bayesian inference is often intractable because of the evidence in the denominator. I refer the reader to a nice tutorial on Thompson Sampling2.
Contextual Bandit
Up until now, our formulation was context-free; it only conditioned on the action (index). Now, suppose for each timestep, we observe an additional random variable about either user or item (=action). Let us define the context at the timestep $t$, that depends both on the user context $u_t$ and action $a_t$. The aim is almost the same as before. We are to learn an estimator .
LinUCB Policy
The algorithm implements a ridge linear regression with UCB. Define the linear estimator . Let $D_a \in \mathbb{R}^{n_j \times d}$ denote the design matrix (the training data) and $d$ the dimension of $x_{t,a}$. Let $\mathbf{r}_j \in \mathbb{R}^{n_j}$ the observed rewards corresponding to $D_a$. Assuming we solve a least-squares problem with a ridge regularization ($\lambda=1$), we have a closed-form solution . When elements $r_j$ are conditionally independent given correponding rows in $D_a$, it holds that
.
where $A_a = (D_a^\top D_a + I_d)^{-1}$ and $\alpha = 1 + \sqrt{\log(2/\delta)/2}$. Thanks to $I_d$, is likely invertible. Inverting a matrix is quite $O(d^3)$ so in practice, we want to solve the linear system periodically as opposed to every step. Finally, we choose .
The original paper suggests two versions: a disjoint model that learns separate $w_a$ for each action and a hybrid model that has shared parameters across actions. I did not quite like the disjoint model; especially because one must maintain the set of valid actions that can change over time (e.g. new articles coming in and old articles perish). For the experiment (yahoo news), as a simple baseline, I wrote a model that shares all the parameters for all actions. Such a simple linear model may underperform in the high data regime but I expected an okay-level performance in the low data regime.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | |
Linear Gaussian Thompson Sampling Policy (lgtsp)
This is a Thompson Sampling policy that implements Bayesian linear regression with a conjugate prior. We assume the underlying model (likelihood) satisfies where . We define a prior jointly on $w, \sigma^2$ such that where . The
posterior update is well written in wiki. By assumging the initial hyperparam $\mu_0=0$, we can zero out some terms which I did for the experiments. Although the exact posterior update is tractable in this formulation, evaluating a covariance matrix can be too expensive. I noticed it is indeed the bottleneck in my implementation and multivariate_normal ran into a degenerate covariance matrix and failed SVD on it. A better approach would be find a diagonal covariance matrix approximation, which I have not tried out yet. For computational reasons, I collect every data point but update the posterior periodically. I built, again, a shared parameter model across all actions.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 | |
Neural $\epsilon_n$-Greedy Policy (nueralp)
We fit a simple fully-connected neural network wth stochastic-gradient-based optimizers like RMSProp to the data coming online. It is the same as $\epsilon_n$-Greedy Policy except we use a neural network to represent $Q(x_{t,a})$. Neural networks may be one good way to overcome the limited representation power of the linear models introduced so far. Instead of leaving the exploration to the hyperparameter $\epsilon$, one may keep the Bayesian linear regression formulation and fit a nueral network $g$ such that .
Other baselines
- random policy (rp): uniformly at random
- -greedy (egp): sample mean policy + annealing exploration.
- sample mean policy (smp): no exploration.
- optimal policy (opt_p): assumes an oracle that knows the optimal action.
Experiments
Well, that was a review of basic Contextual Bandit algorithms. Now we move on the experiemnts.
Partially-observable Reward Dataset
Here’s a qustion. How do we train the algorithms on a dataset someone else collected for us? So far, our formulation assumed we are learning a policy in an on-policy setting. It means the policy we collect data from (behavior poilcy) is the same as the policy we optimizer (the target policy). In most practical situations, one would have a dataset sampled by a policy and train another policy using the dataset. This realistic setting makes it hard for us to evaluate the true performance of our policy. If a behavior policy always chooses one action among others, we would not have any samples for counterfactuals (=what happens if we had taken other action). This problem is called Off-policy Policy Evaluation and an important research topic.
In an on-policy setting, we can observe the rewards for all actions at will. All it takes is to try the actions we want. In an off-policy setting, however, we cannot directly observe rewards unless the behavior policy that collects data deliver them to us. Then, how do we use such partially observable reward data for training? One naive way to reject any samples where our policy’s action does not match the ation empirically taken by the behavior policy. If we assume a uniform random behavior policy, indeed the performance evaluation would be unbiased. Or we could use an Importance Sampling to obtain an unbiased estimate for the performance. These methods are okay if there are a lot of samples. For the experiment we use the naive rejection method.
Synthetic (fully observable reward, item context)
We consider a simple hypothetical contextual bandit problem. The true distribution that samples rewards is Gaussian with some predefined variance. Assuming no interactions between actions, we keep the model as an isotropic multivariate Gaussian. As the true model is Gaussian, we expect the thompson sampling poilcy (lgtsp) to perform well.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
As expected, lgtsp outperformed baselines.
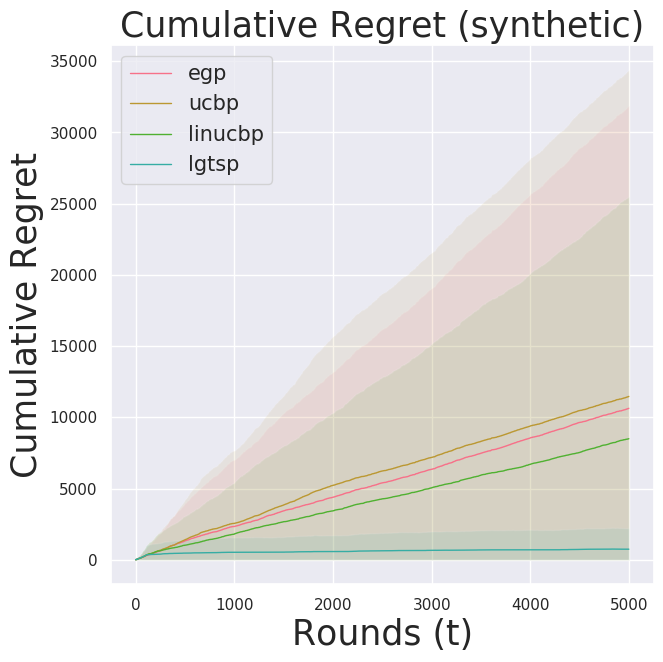
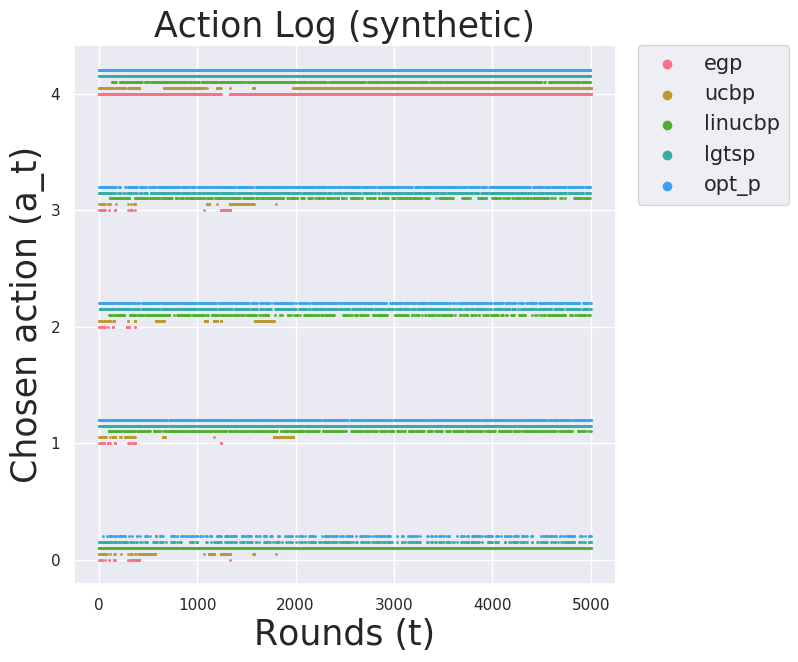
Other baselines especially linucbp did not perform so well because they locked on to one action that it thinks the best and does not get out of it. You can observe that in the action distribution plot below.
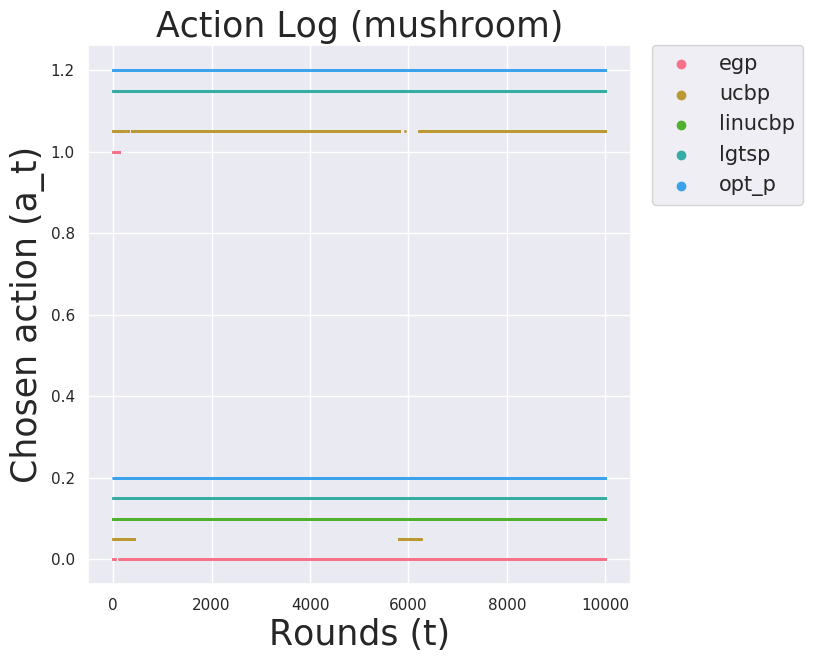
Mushroom (fully observable rewards, item context)
Mushroom consists of 8,124 hypothetical mushroom datapoints that show features (item context) and whether each is poisonous/edible. I modeled the reward distribution similar to the paper where +10.0 for eating a good mushroom, -35.0 for eating a bad mushroom with a 30% chance, still +10.0 with 70% (bad mushroom but lucky), and 0.0 for not eating. The optimal policy would eat only good mushrooms and not take the risk with bad mushrooms. Good and bad mushrooms are in an almost equal proportion. Of course, whether a mushroom is good or bad is hidden (except for opt_p).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | |
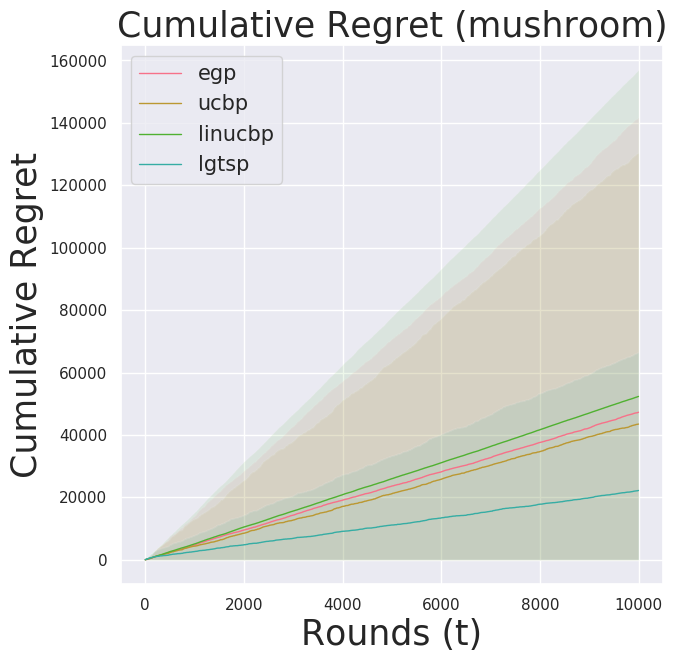
We observe again lgtsp outperfoming baselines. It is quite surprising linucbp performed so poorly. Perhaps there is a bug in the code (recall, this is an intermediate report).
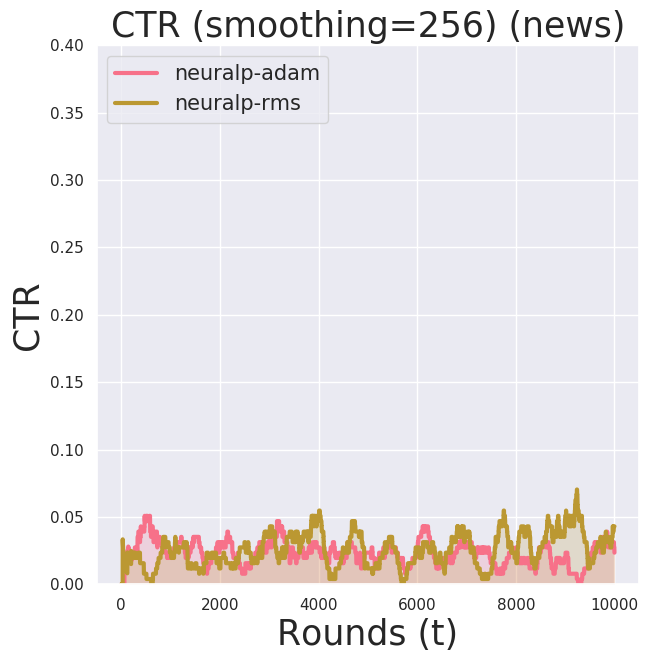
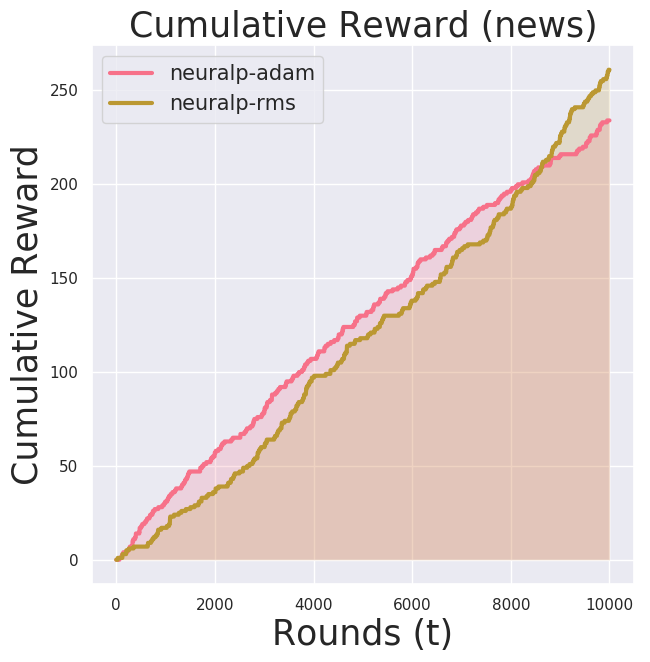
Yahoo Click Log Data (partially observable reward, user+item context)
Yahoo! Front Page Today Module User Click Log Dataset that features a log data for ~45 Million user visit events. For each user visit event, we have features available for the article shortlist (the candidate article pool) and user features. Crucially, the shortlist elements change over time so the algorithm must learn to adapt to a new action set. This is a partially observable reward problem because we do not have the data for the counterfactuals and instead know what article in the shortlist was displayed to the user and whether the user clicked it or not. If we use an on-policy algorithm, the data points we can use is only when our policy’s recommendation matches the chosen article in the data.
Since the behavior policy was a uniform random policy for roughly 20 actions at each time step, the effective sample rate (the rate at which samples could be used for training) was roughly at 5%. This means, in order to compute training over n=10000, we have to evaluate approximately 200,000 points and reject the rest.
Notice now the y-axis is cumulative reward. Since this is a partially observable reward problem we cannot compute the regret.
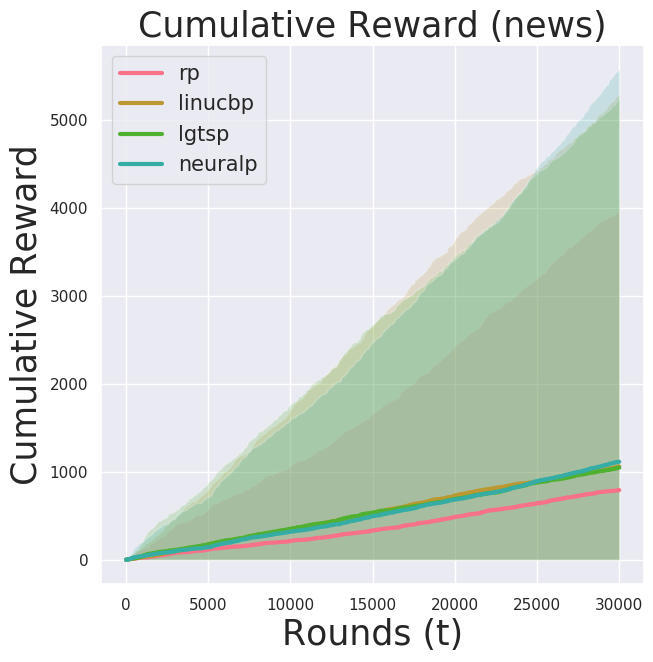
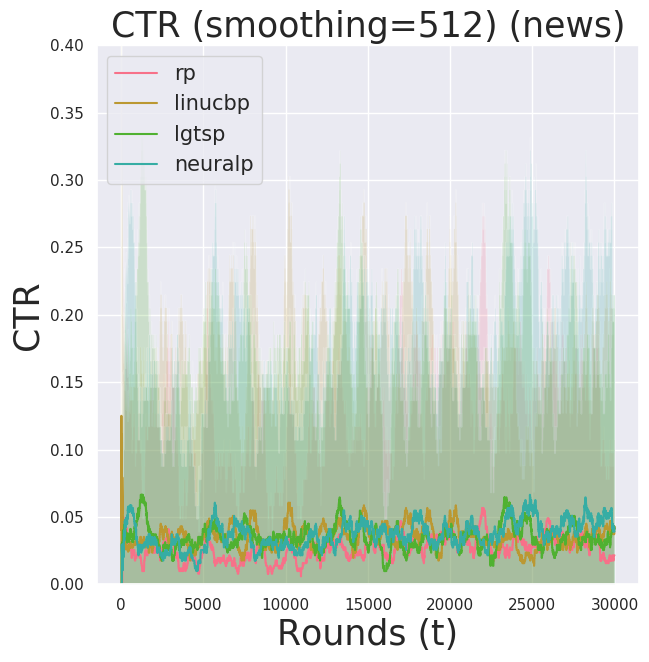
Due to computational costs (both theoretically and practically—I run my experiments on EC2 Spot Instances), I ran neuralp for $n=100000$ for now. I observed a high variance in the performance of neuralp (the shaded region). It seemed there is a bad local optimum it tends to get stuck at.
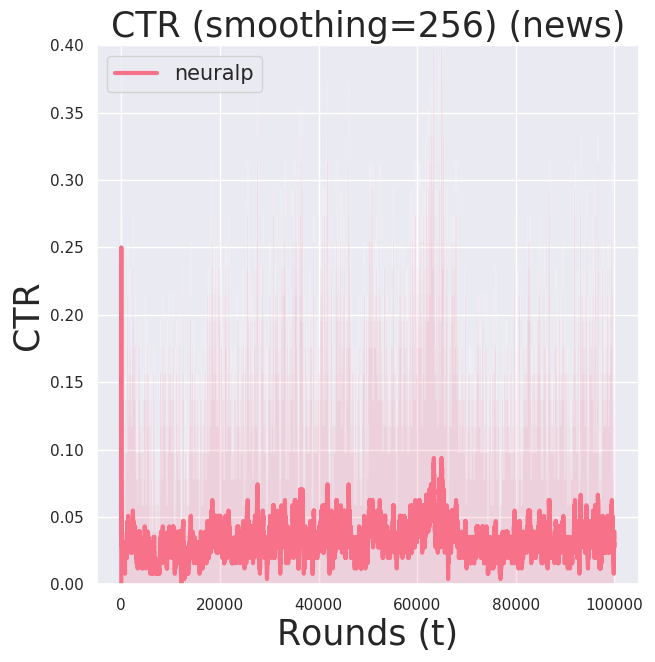
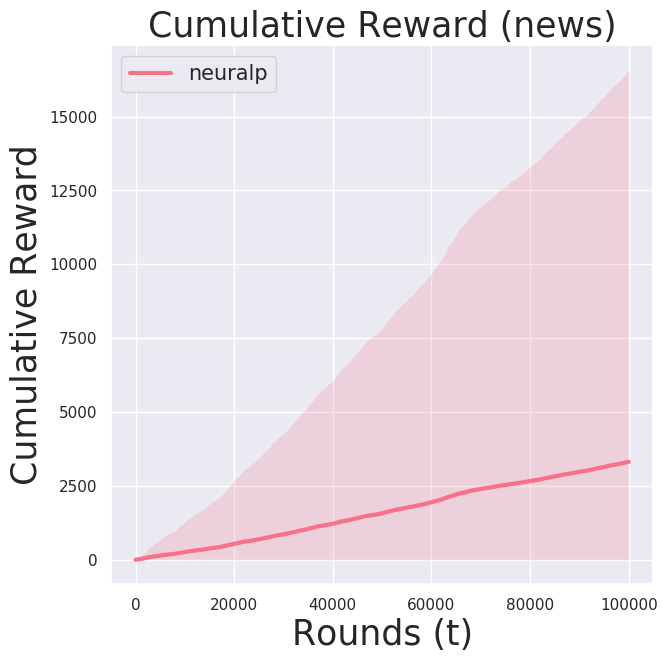
There wasn’t a significant difference in the learning performance between Adam and RMSProp.
Source Code
Check out the source code for more details.