GSoC Phase 3 update
This summer I worked as a contributor to Red Hen Lab, a global organization that conducts research on multi-modal communication and develops open-source tools for it. The contribution was made possible through generous sponsorship by Google Summer of Code. As I continue to contribute to the project, I will do my best to document the progress and my thought process so future researchers and collaborators can jump in easily.

So… what is the project about?
I am working on the problem of detecting TV news program boundaries, internally referred to as the Digital Silo problem. I will quote the original description of the problem here: > Libraries and research institutions in the humanities and social sciences often have large collections of legacy video tape recordings that they have digitized, but cannot usefully access — this is known as the “digital silo” problem. … A basic task we need to solve is television program segmentation. The UCLA Library, for instance, is digitizing its back catalog of several hundred thousand hours of news recordings from the Watergate Hearings in 1973 to 2006. These digitized files have eight hours of programming that must be segmented at their natural boundaries.
In short, enormous amounts of digitized videos are sitting idly in the archive in the manner that researches can’t efficiently navigate them like a black box: hence, Digital Silo. It is difficult to get an accurate sense of the size of the archive considering how long the recording has been going on. However, it is clear the archive can be super useful for many researchers. Once the problem gets solved, people will be able to search for the kinds of videos they want and run some statistical analysis with them. As I began to work on the project, I felt like I was about to open this big treasure chest.
Why is it difficult to navigate the data?
The video files are usually eight hours long and therefore contain 6 to 9 different TV programs recorded on the same channel. Typically the videos don’t come with crucial metadata such as what TV programs there are and more importantly, when one program starts and ends. As a result, we are in the dark unless we start digging through the videos manually one by one.
To make the archive more accessible, Red Hen Lab aims to split the long videos into shorter ones by their natural program boundaries. In other words, the goal is to locate the points in the videos at which a program changes to another. Suppose there’s a video that starts with a hypothetical TV news program titled ‘Good morning, it is 9am’. At some point, the program will finish and a commercial will be shown. After the commercial, another program called ‘Hello World, it is already 10am will start. Our goal is to build a model that learns to output time stamps where program transitions take place as below.
09:00:01 — 09:54:59: Good morning, it is 9am
09:55:00 — 09:56:32: commercial on toothpaste
09:56:33 — 10:40:00: Hello World, it is already 10am.
What data do we have?
We have three different kinds of data.
-
Video (mp4): it varies wildly in quality. The older ones tend to be of poorer quality.
-
Text (txt3/txt4): subtitles files contributed by different organizations. Not all videos have corresponding subtitle files. About half of the videos have subtitles (more recent ones after the mandate for making subtitles mandatory got enacted).
-
Cutfiles (.cuts): metadata files that are essentially labelled data in the perspective of Supervised Learning. There are currently cutfiles for roughly 400 videos and they were manually crafted. Notice the time stamps for commercials had not been accounted for.
 an example of a video
an example of a video
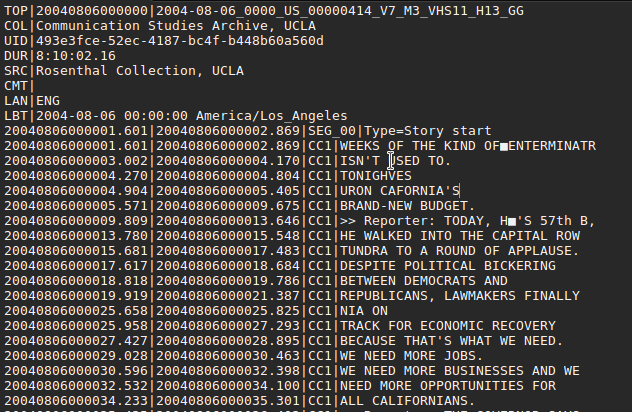 an example of a caption file
an example of a caption file
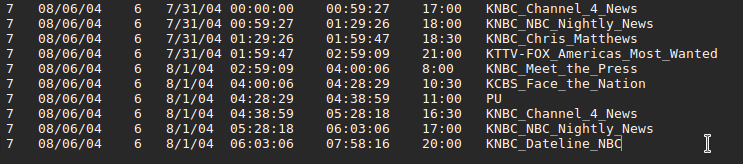 an example of a cutfile (the fifth and sixth columns are the target time stamps)
an example of a cutfile (the fifth and sixth columns are the target time stamps)
What are possible approaches to solve the problem?
To be honest, it took many twists and turns for me to have a clear view on this matter, but there’s no reason to put you through every step of the painful journey also. I will just share what I now think are viable approaches worth the try.
First, we could use supervised learning with neural networks (highly generalizable). Pros are that neural networks can learn to engineer features on their own and can make an extremely powerful discriminator as shown in image classification. Cons are that the approach requires lots of labelled data which we don’t have. Plus, unlike labeling an image (e.g. saying an image has a cat in it.), labeling an 8-hour-long video is a much arduous task.
Second, we could manually build a project-specific model with handcrafted features derived from domain knowledge (limited generalizability). The model can be anything. Good candidates for the manually crafted features are recurring theme music for opening and closing, anchor faces, logo, certain keywords and so forth. The upside is this approach can be taken without many labelled data. The labelled data required are those for testing. The downside is that it will take a lot of manual efforts on our side, and we can reasonably expect many rounds of trial and errors to finally discover a good combination. Plus, we won’t know how accurately it’s going to predict boundaries.
Third, we could take a rote memory approach **(not efficiently scalable). This is arguably the most bruteforce-y way but offers some level of assurance on the final performance. TV programs tend to have a regular structure and recurring elements (e.g. opening or closing theme music). Granted programs may last for anywhere from 2 years to 10 years, there may not be too many of distinct TV programs to deal with. Suppose there are 1,000 distinct TV programs among all the recordings we have. If our model were to memorize the beginning and ending of each program using technology like Audio fingerprinting, in principle our model will have extremely high accuracy. Of course, the question is how to find those 1,000 distinct programs in the first place? **Apparently this approach does not scale. We will have to manually locate the boundaries. In doing so, we can make more cut files.
Also, I would like to note that semi-supervised learning may be something to consider also to overcome shortage of labelled data. Incidentally, transfer learning is not feasible because the problem is not yet well-researched so there is no existing pre-trained model to fine-tune.
Where does the project lie at the moment?
First, after some intense discussion with Professor Steen, who is my mentor for the project, I decided to tackle the problem with the rote-memory approach first, because we can expect the approach will work very well for news programs that had already been memorized. There may be only so many programs to remember. Of course, the question is left open how to efficiently collect samples to be memorized in the first place.
Towards the end, I wrote a module that pre-processes multi-modal data, so you can read and manipulate data as you see best fit. Also I wrote an evaluation module that produces an F1 score for when we tackle this problem as a binary classification problem — we’ll come to this topic in more detail soon. Currently the APIs are concentrated mostly on text data.
Let us jump into the modules in more detail. Here’s a skeleton of modules (omitting some for simplicity). I wrote annotations below so you can get a sense of what each module does. Notice there’s a test module for each module following TDD. The continuous integration status, whether all the test modules are passing, can be tracked on Travis. The visual stock is work in progress.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Here’s a preview of how audio-fingerprint module works.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
The most naive text-based approach is:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
An Alternative Approach: Story Boundary Classification
I concluded the first and second approach were not suitable (see the known issues section). I was not satisfied with the rote-memory approach, because of its poor scalability. I looked for an alternative approach: story boundary detection. Stories boundaries are when, within a program, a story changes to another in terms of topics. For example, an announcer may touch upon Economy and move on to Politics.
My hypothesis was that (almost all) program boundaries will be a subset of story boundaries. Intuitively this is a reasonable assumption as there are some sort of topical discontinuity from the end of a program to the beginning of a commercial and vice versa. The idea was that if were to find story boundaries first and learn to filter them down to program boundaries, the game is over.
The reason I liked the approach was twofold. First, unlike program boundary segmentation, I could find existing research on the problem and relevant dataset (e.g. TRECVID). Second, more importantly, the archive came with caption files and they already had labelled data, obviating the need to collect significantly more, unlike program boundaries.
To test the hypothesis, I re-framed the problem as a binary classification task. I first divide 8-hour-long videos into a series of time blocks where each block is 10-second-long. For each time block, I wanted my model to classify if the block contains story boundaries. But you may say at this point “wait… how do you know when a story changes to another?”.
Interestingly the story boundaries were already annotated in the caption files with the specific marker ‘type=story start’ (you can check the subtitle file example above). Also we have some labelled data (cutfiles) for 400 videos. So I checked how many of the program boundaries in those cutfiles can be recalled through a naive model which marks time blocks in the 3-minute neighborhood of “type=story start” or “type=commercial start”. The reason I had to have the 3-minute neighborhood measure was because the cutfiles are not so accurate and crucially inconsistent. (see known issues).
So what was the recall like? It was 79% for roughly 273 caption files for which we have cutfiles and subtitles. Now the question is ‘what is that missing 21%?’. In turned out the subtitle files were incomplete in the sense that there are no captions even though there exist speeches. As I manually inspected failure cases, I discovered that’s where most of the 21% took place. Note the precision is very low because of massive false positives (=classifying time blocks as program boundaries when they are not).
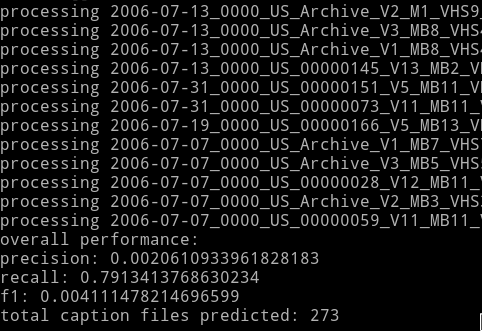 recall was 79% with “type=story start” or “type=commercial start”
recall was 79% with “type=story start” or “type=commercial start”
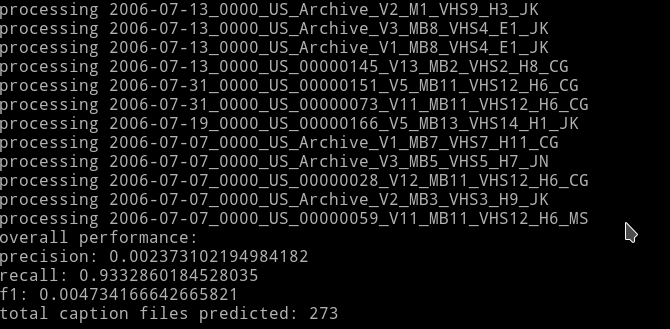 Incidentally, I had 93% recall by just adding the keyword ‘caption’. This is some program boundaries are followed by phrases like “captions contributed by so-and-so”**
Incidentally, I had 93% recall by just adding the keyword ‘caption’. This is some program boundaries are followed by phrases like “captions contributed by so-and-so”**
Perhaps my intuition is misleading but I feel this is an auspicious path to try out. This is the direction I want to walk in going forward in the next chapter of the project.
What are possible next steps?
Without priorities in mind, here are a few major to-do’s off the top of my head. I would like to emphasize the importance of collecting high-quality cut files. I am convinced it should be the very first step. Cut files are required regardless of what approach we will take. For the rote memory approach, we need to specify the time window to extract fingerprint from. To know the time window, we first need to locate where boundaries are. If we have lots of them (perhaps like a few thousands), we may be able to train a neural network. Orthogonal to the issue of training, we need them if we are going to build a model and evaluate the performance of it. There’s no other way. By nature, it’s laborious to collect cut files. It may be worth checking services like Amazon Mechnical Turks.
-
fix the existing cut files and collect them more
-
complete a module for Visual Template (if not enough with audio fingerprinting alone)
-
write integration into HPC with fingerprinting and Visual Template
-
extract more hand-crafted features (logo, anchor faces, and so on)
-
train a model for story boundary classification first and filter them down to program boundaries.
Known issues
First, program boundary annotations in the cut-files are so fruitful. **Without consistent boundary annotations, we will be forever in the dark not knowing how well our model is performing, let alone training it with the data**. Of course, you can check the outputs from your model and manually check them against each video. But, that’s grossly inefficient.
Why don’t we make the cutfiles so they are more useful? Suppose we work on the actual cutfile titled “2006–06–13_0000_US_Archive_V3_M2_VHS10_H4_MS.cuts”. And it looks like:
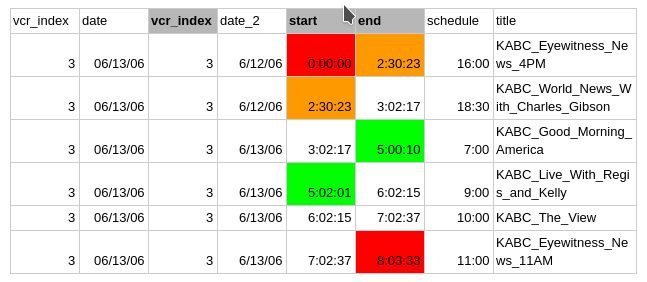
(NOTICE RED) timestamps that mark the beginning of the first program and the end of the last program in a video should be precise.
In many videos, the first programs start several minutes after 0:00:00. In this case, we need a precise timestamp like 0:02:22. Or some videos start from midpoint of their first programs. In this case, instead of marking it as 0:00:00, we could use a special marker like “NAS” (Not Available Start). The same logic goes for the end of the last program. We need it to be precise. In case the video cuts off the last program in the middle, we use “NAE”(Not Available End).
(NOTICE ORANGE) The two orange blocks have the same timestamp. They are not precise, because there are commercials in between.
Suppose: Program A ->(boundary X) Commercial ->(boundary Y) Program B
Boundary X and boundary Y are different. The distinction is crucial and very useful for when we try to use a computational approach.
So… now (NOTICE GREEN). The orange blocks could look like the green blocks. As far as I can tell, the existing cutfiles are noting both boundary X and boundary Y in an unpredictable manner. If annotating for both X and Y is difficult, I would say we stick with X and use that only.
Second,** the existing caption files are not complete with empty lines here and there**. Plus lots of the videos lack them at all. To keep text input data consistent and complete, perhaps it is worth considering using a pre-trained ASR (Automatic Speech Recognition) model and/or fine-tuning it with the existing caption data. This way, we will have caption files for all and without empty lines. It’s okay if the accuracy is not perfect in the grand scheme of the things.
For more details on a variety of issues, please see this.
I learned a ton because the contour of the problem was very rough around the edges. I guess real problems rarely have neat shapes. Paradoxically, this is why the project feels so interesting. The program boundary detection problem clearly has not been studied much. Whatever solution you will build will make an immediate contribution to the world’s body of knowledge. Anyways, stay tuned for the next progress report!